🌐 معماری ترانسفورمر (Transformer Architecture)
مقدمه
ترانسفورمر یکی از تحولات بزرگ در حوزهی هوش مصنوعی و یادگیری عمیق است که بهویژه در پردازش زبان طبیعی (NLP) و اخیراً در بینایی ماشین (Computer Vision) تأثیر شگرفی گذاشته است. این مدل برای اولین بار در مقالهی معروف “Attention Is All You Need” توسط گروهی از محققان گوگل در سال ۲۰۱۷ معرفی شد و به سرعت جایگزین ساختارهای سنتی مانند RNN و LSTM شد.
اصلیترین نوآوری ترانسفورمر استفاده از مکانیزم توجه (Attention Mechanism) به جای توالیهای بازگشتی است، که باعث افزایش چشمگیر سرعت و کارایی مدل شد.
ساختار کلی ترانسفورمر
معماری ترانسفورمر از دو بخش اصلی تشکیل شده است:
- Encoder (رمزگذار)
وظیفه دارد ورودیها را دریافت کرده و ویژگیهای معنایی و وابستگیهای میان کلمات یا دادهها را استخراج کند. - Decoder (رمزگشا)
از اطلاعات استخراجشده توسط رمزگذار برای تولید خروجی نهایی مانند ترجمه، پاسخ، یا پیشبینی استفاده میکند.
هر دو بخش از بلوکهای تکرارشونده تشکیل شدهاند که شامل لایههای کلیدی زیر هستند:
اجزای اصلی ترانسفورمر
1. مکانیزم توجه (Attention Mechanism)
قلب تپندهی ترانسفورمر است. ایده اصلی آن است که هر ورودی بتواند به تمام بخشهای دیگر توجه کند تا روابط وابستگی طولانیمدت میان اجزای داده حفظ شود.
مهمترین نوع آن Self-Attention است که در آن هر عنصر ورودی وزن توجه خود را نسبت به سایر عناصر محاسبه میکند.
فرمول کلی توجه:
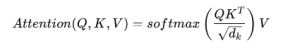
که در آن:
- (Q): Query
- (K): Key
- (V): Value
- (d_k): ابعاد کلید
2. Multi-Head Attention
به جای یک مکانیزم توجه، چندین “سر توجه” به طور موازی اجرا میشوند تا مدل بتواند از زوایای مختلف به روابط بین دادهها نگاه کند. سپس نتایج ادغام میشوند تا نمایش غنیتری از ورودی تولید شود.
3. Feed Forward Network (FFN)
بعد از لایهی توجه، هر موقعیت در داده از یک شبکهی عصبی دو لایهای عبور میکند تا ویژگیهای غیرخطی یاد گرفته شود.
4. Residual Connection و Layer Normalization
برای جلوگیری از از بین رفتن گرادیان و حفظ پایداری آموزش، خروجی هر بلوک با ورودی آن جمع میشود (Residual Connection) و سپس نرمالسازی لایه (LayerNorm) انجام میشود.
5. Positional Encoding
چون ترانسفورمر برخلاف RNNها توالی را بهصورت ترتیبی پردازش نمیکند، لازم است موقعیت هر کلمه یا داده در دنباله مشخص شود.
برای این منظور از کدگذاری مکانی (Positional Encoding) استفاده میشود تا اطلاعات مربوط به ترتیب دادهها به مدل منتقل شود.
عملکرد Encoder و Decoder
🔹 Encoder
هر رمزگذار شامل:
- لایهی چندسر توجه (Multi-Head Self-Attention)
- لایهی FFN
- نرمالسازی و ارتباطات باقیمانده
🔹 Decoder
رمزگشا علاوه بر موارد بالا، شامل یک لایهی توجه اضافی است که بر خروجی رمزگذار تمرکز میکند. این بخش مسئول برقراری ارتباط بین اطلاعات ورودی و تولید خروجی است.
مزایای معماری ترانسفورمر
- ⚡ سرعت بسیار بالا در آموزش و پیشبینی به دلیل محاسبات موازی
- 🧠 درک عمیقتر وابستگیهای طولانیمدت در دادهها
- 🔄 قابلیت تعمیمپذیری بالا در زبان، تصویر، صدا و حتی گراف
- 🌍 مقیاسپذیری فوقالعاده برای دادههای بزرگ
- 🔧 امکان استفاده در مدلهای چندوجهی (Multimodal) مانند GPT، BERT، ViT و CLIP
کاربردهای ترانسفورمر
- پردازش زبان طبیعی (NLP):
- ترجمه ماشینی
- تولید متن
- خلاصهسازی خودکار
- پاسخ به سؤال
- مدلهای زبانی بزرگ مانند GPT و BERT
- بینایی ماشین (Computer Vision):
- طبقهبندی تصاویر (Vision Transformer – ViT)
- بخشبندی اشیاء (Swin Transformer, SegFormer)
- تشخیص اشیاء (DETR)
- چندرسانهای (Multimodal):
- مدلهای تصویر-متن مانند CLIP و DALL·E
- ترکیب زبان و صدا در سیستمهای گفتاری
جمعبندی
ترانسفورمرها مرزهای یادگیری عمیق را جابهجا کردهاند. با حذف وابستگیهای زمانی RNNها و بهرهگیری از مکانیزم توجه، این معماری توانست در بسیاری از حوزهها مانند پردازش زبان، بینایی ماشین، و مدلهای چندوجهی انقلابی ایجاد کند. امروزه تقریباً تمام مدلهای پیشرفتهی هوش مصنوعی، از GPT تا ViT، بر پایهی معماری ترانسفورمر ساخته شدهاند.




