مسیر درک زبان انسان توسط ماشین
مقدمه
پردازش زبان طبیعی (NLP) یکی از شاخههای اصلی هوش مصنوعی است که هدف آن آموزش ماشینها برای درک، تفسیر و تولید زبان انسان است.
در دهههای گذشته، مسیر پیشرفت NLP از مدلهای آماری ساده تا نمایشهای معنایی عمیق واژهها (Word Embeddings) طی شده است.
این تحول، نقطهی آغاز درک معنایی زبان توسط ماشینها محسوب میشود — تحولی که زمینهساز مدلهای قدرتمند امروزی مانند BERT و GPT شده است.
در این مقاله، به بررسی مبانی مدلهای آماری در NLP، مفهوم Word Embeddings و تأثیر آنها بر درک زبانی سیستمهای هوش مصنوعی میپردازیم.
بخش اول: مدلهای آماری در پردازش زبان طبیعی
پیش از ظهور یادگیری عمیق، پردازش زبان طبیعی عمدتاً بر پایهی مدلهای آماری (Statistical Models) استوار بود. این مدلها تلاش میکردند با استفاده از احتمالات، الگوهای زبانی را شناسایی کنند و پیشبینیهایی دربارهی ساختار یا معنای جمله انجام دهند.
📊 مدلهای زبانی آماری (Statistical Language Models)
یک مدل زبانی آماری احتمال وقوع یک توالی از واژهها را محاسبه میکند.
برای مثال، مدل میتواند احتمال وقوع عبارت «کتاب را خواندم» را نسبت به عبارت «کتاب خواندم را» محاسبه کند و گزینهی درستتر را انتخاب نماید.
فرمول کلی در این مدلها بهصورت زیر است:
![]()
اما محاسبهی مستقیم این احتمال برای جملات طولانی دشوار است. بنابراین، از تقریبهای سادهتری مانند مدلهای n-gram استفاده میشود.
🧩 مدلهای n-gram
در مدل n-gram فرض میشود که هر واژه تنها به تعداد محدودی از واژههای قبل از خود وابسته است.
مثلاً در مدل bigram، احتمال واژهی فعلی تنها به واژهی قبلی وابسته است:
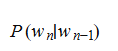
این روشها پایهی بسیاری از سامانههای اولیهی ترجمهی ماشینی، تشخیص گفتار و تصحیح خودکار بودند.
با این حال، مدلهای آماری محدودیتهای مهمی داشتند:
- وابستگی به دادههای زیاد برای تخمین دقیق احتمالات
- ناتوانی در درک معنای واژهها
- مشکل در تحلیل روابط بلندمدت در جملات
بخش دوم: گذار از آمار به معنا؛ ظهور Word Embeddings
برای غلبه بر محدودیتهای مدلهای آماری، پژوهشگران به دنبال راهی برای نمایش واژهها بهصورت عددی و معنایی بودند. نتیجهی این تلاشها، معرفی مفهوم Word Embedding بود.
🔠 تعریف Word Embedding
Word Embedding نوعی نمایش عددی فشرده از واژهها در فضای برداری است، بهطوری که واژههای دارای معنای مشابه، بردارهایی نزدیک به هم دارند.
بهعبارت دیگر، در این روش هر واژه بهجای یک برچسب یا شناسه، بهصورت یک بردار چندبعدی (مثلاً ۳۰۰ بُعدی) نمایش داده میشود.
برای مثال، در فضای برداری ممکن است:
- فاصلهی میان “پادشاه” و “ملکه” نزدیک به فاصلهی “مرد” و “زن” باشد.
- یا رابطهی “پاریس → فرانسه” شبیه “تهران → ایران” در فضای عددی بازنمایی شود.
این یعنی مدل میتواند روابط معنایی و نحوی میان واژهها را یاد بگیرد — قابلیتی که مدلهای آماری فاقد آن بودند.
بخش سوم: مدلهای معروف در Word Embedding
🧠 ۱. Word2Vec
در سال ۲۰۱۳، شرکت گوگل مدل Word2Vec را معرفی کرد که نقطهی عطفی در یادگیری معنایی واژهها بود.
Word2Vec از دو ساختار اصلی استفاده میکند:
- CBOW (Continuous Bag of Words): پیشبینی واژهی فعلی با استفاده از واژههای اطراف.
- Skip-gram: پیشبینی واژههای اطراف با استفاده از واژهی فعلی.
با آموزش روی حجم عظیمی از متن، Word2Vec توانست الگوهای معنایی پیچیدهای را بیاموزد — برای مثال:
king - man + woman = queen
این معادلهی مشهور نشان میدهد که مدل توانسته رابطهی جنسیت را از میان واژهها استخراج کند.
🧾 ۲. GloVe (Global Vectors for Word Representation)
مدل GloVe که توسط دانشگاه استنفورد معرفی شد، ترکیبی از روشهای آماری و Word2Vec است.
در GloVe، مدل با تحلیل هموقوعی (co-occurrence) واژهها در کل پیکرهی متنی، بردارهای معنایی ایجاد میکند.
نتیجهی این روش، نمایشهای دقیقتر و پایدارتر از واژههاست.
💬 ۳. FastText
مدل FastText از شرکت فیسبوک، گام دیگری در جهت درک ساختار درونی واژهها برداشت.
در این مدل، هر واژه به تعدادی زیرواژه (subword) تقسیم میشود؛ بنابراین حتی واژههای جدید یا اشتباه املایی هم قابل تحلیلاند.
این ویژگی باعث شد FastText در زبانهایی مانند فارسی که ساختار صرفی پیچیده دارند، عملکرد بسیار خوبی داشته باشد.
بخش چهارم: از Word Embeddings تا مدلهای زبانی عمیق
Word Embeddings راه را برای مدلهای عمیقتر باز کردند.
در مدلهایی مانند ELMo، هر واژه بر اساس زمینهی جمله (Context) نمایش داده میشود، نه صرفاً بهصورت یک بردار ثابت.
برای مثال، واژهی «بانک» در جملهی «به بانک رفتم» با واژهی «بانک اطلاعاتی» معنای متفاوتی دارد؛ مدلهای جدید قادرند این تمایز را در نمایش عددی خود لحاظ کنند.
این تحول در نهایت به تولد مدلهای ترنسفورمر و نمایشهای زبانی قدرتمند مانند BERT و GPT انجامید.
در این مدلها، Embeddingها نهتنها معنای واژه را بلکه معنای جمله و مفهوم کلی متن را نیز بازنمایی میکنند.
بخش پنجم: کاربردهای Word Embeddings در NLP
Word Embeddings در بسیاری از وظایف پردازش زبان نقش کلیدی دارند، از جمله:
- تحلیل احساسات: تشخیص لحن مثبت یا منفی در متون بر اساس نزدیکی معنایی واژهها.
- ترجمهی ماشینی: یافتن همارزهای معنایی در زبانهای مختلف.
- جستوجو و بازیابی اطلاعات: درک مفهومی از عبارت کاربر برای ارائهی نتایج دقیقتر.
- چتباتها و دستیارهای مجازی: درک هدف و نیت کاربر از طریق شباهت معنایی میان جملات.
- تشخیص ناهنجاری یا موضوع: گروهبندی متون مشابه بر اساس نزدیکی بردارهای معنایی.
بخش ششم: چالشها و محدودیتها
با وجود مزایای زیاد، Word Embeddings نیز چالشهایی دارند:
- ابهام معنایی: در مدلهای قدیمی، یک واژه فقط یک بردار دارد، حتی اگر چند معنی متفاوت داشته باشد.
- سوگیری دادهها: چون مدلها از متنهای واقعی یاد میگیرند، ممکن است سوگیریهای فرهنگی و جنسیتی را هم بازتولید کنند.
- بهروزرسانی دشوار: تغییر یا افزودن واژهها در مدلهای از پیش آموزشدیده دشوار است.
مدلهای جدیدتر مانند Contextual Embeddings و Transformer-based Models تلاش کردهاند این محدودیتها را کاهش دهند.
جمعبندی
مدلهای آماری و Word Embeddings، دو مرحلهی کلیدی در تکامل پردازش زبان طبیعی هستند.
مدلهای آماری نخستین گام در یادگیری ساختار زبانی بودند، در حالی که Word Embeddings به ماشینها امکان داد معنا و ارتباط میان واژهها را درک کنند.
امروزه، هرچند مدلهای ترنسفورمر و یادگیری عمیق جایگزین روشهای سنتی شدهاند، اما هنوز هم مفهوم بردار معنایی (Semantic Vector) و ایدهی نهفته در Word Embeddings، پایه و اساس تمام مدلهای زبانی مدرن محسوب میشود.
میتوان گفت Word Embeddings پلی بودند که دنیای آمار و معنا را به هم پیوند دادند — پلی که مسیر رسیدن به هوش زبانی واقعی را هموار کرد.




